
When a RAG system answers thousands of internal or customer queries each day, even a 2–3% retrieval error rate becomes a structural risk [1]. The more the system is used, the more these small inconsistencies compound. A production-ready RAG pipeline must prove two things: that it reliably retrieves the right information and that generated answers remain strictly grounded in that information. If any of these fail, the system may still sound correct while producing outputs that cannot be defended or audited.
A structured RAG evaluation verifies these conditions in measurable terms. Applying this consistently requires engineering discipline. As an experienced RAG development company with more than 200 AI and data experts, we define evaluation benchmarks alongside system architecture. From our experience in regulated and high-volume environments, retrieval errors surface only after scale, and without predefined evaluation controls, they are detected too late.
In this article, we outline how to evaluate a RAG system properly, which metrics are relevant in enterprise environments, and how to establish an evaluation process that supports production use with industry best practices.
What is RAG evaluation?
RAG is a model architecture that combines two mechanisms: retrieving relevant information from an external source and generating a response based on that retrieved content.
In a typical RAG workflow, the retriever identifies documents or passages from a knowledge base by matching the user query against indexed content, often using embedding-based similarity search. The selected documents are then incorporated into a prompt, and a language model generates the final answer. The quality of the final response, therefore, depends on the language model’s capabilities and the relevance and completeness of the retrieved context.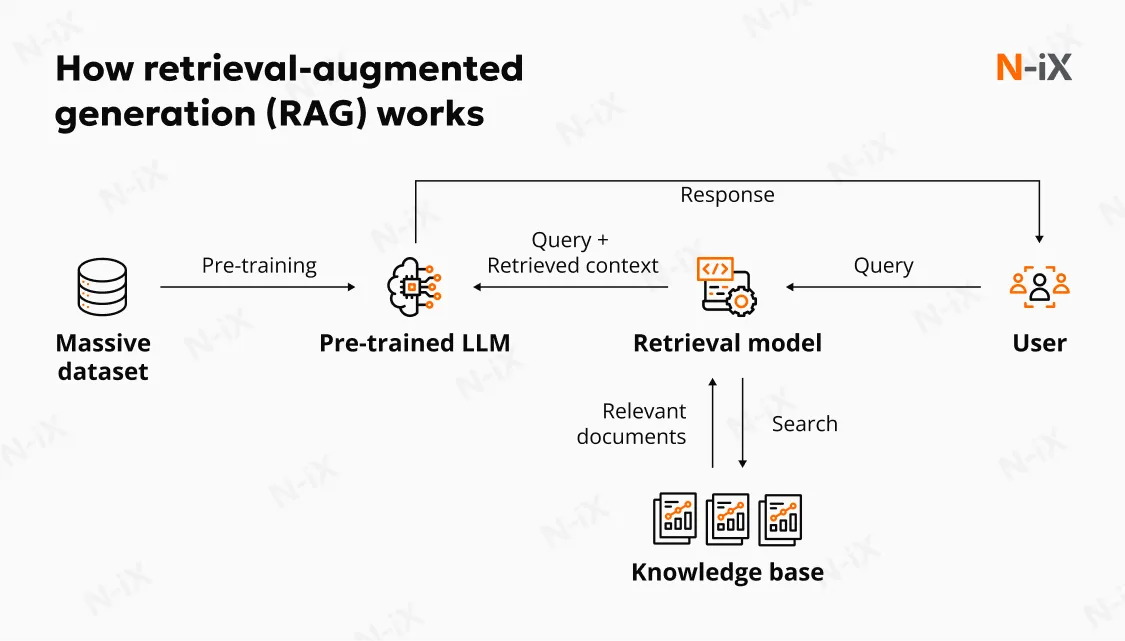
Retrieval-augmented generation (RAG) evaluation is the systematic process of determining whether a retrieval-augmented generation system identifies the correct information from an external knowledge base and uses that information to produce accurate, properly grounded, and contextually appropriate responses. It examines the evidence on which that answer is based.
Evaluating a RAG system is more complex than evaluating a standalone language model because it requires assessing interdependent stages: the retrieval of relevant documents, the generation of the response from that retrieved context, and the system's overall behavior as a pipeline.
Core components of RAG evaluation
A rigorous RAG evaluation framework must examine both the mechanics of retrieval and the integrity of generation, as well as how both interact under real usage conditions. Measuring output fluency alone is insufficient. The evaluation must determine whether the system retrieves the correct evidence, uses it correctly, and delivers answers aligned with user intent and defensible against the source documents. Three core dimensions underpin such an assessment: context relevance, faithfulness, and answer relevance. Each dimension maps to a specific layer of the RAG architecture.
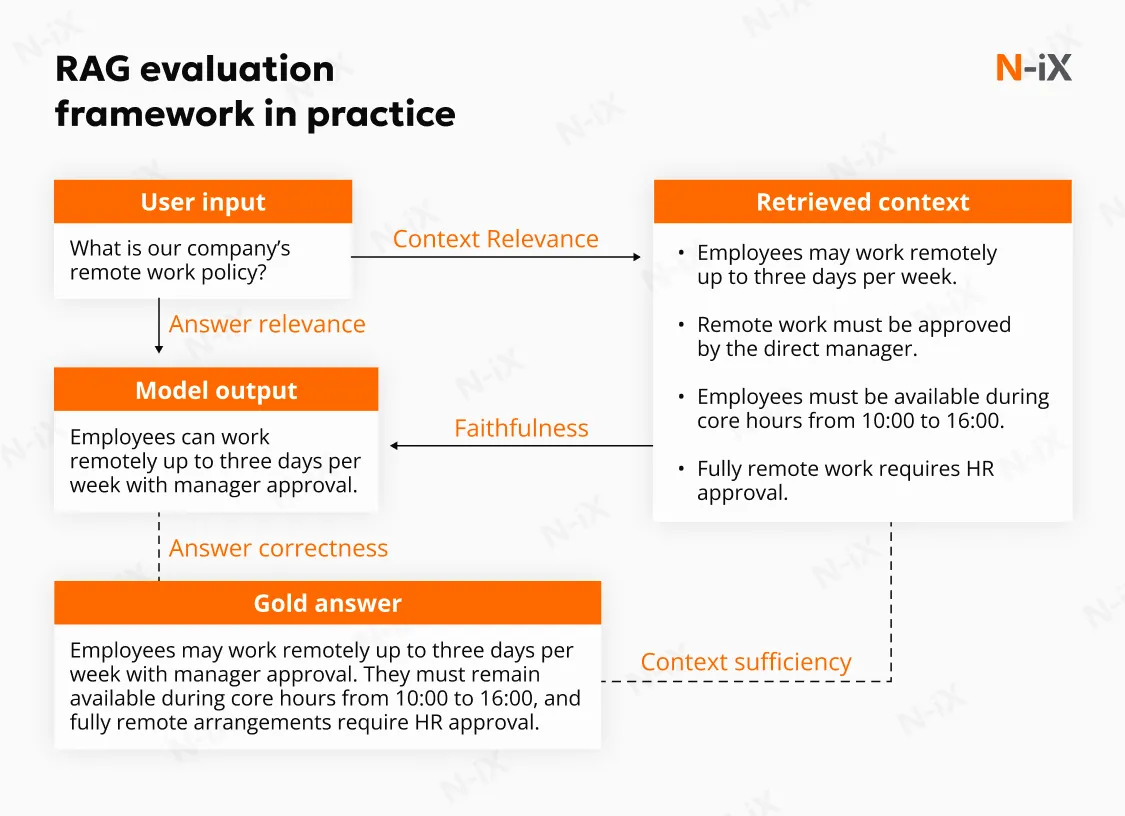
Context relevance: Is the right evidence retrieved?
Context relevance evaluates the quality of the documents retrieved before generation begins. Retrieval determines the upper bound of system accuracy. If relevant documents are not retrieved within the top-ranked results, the generator has no reliable basis for producing a correct answer.
Assessment at this layer typically involves measuring Recall-at-k, ranking effectiveness, and semantic alignment between queries and indexed documents. Ranking metrics help quantify whether the most relevant documents appear at the top of the result set. Manual annotation of relevance remains essential in domain-heavy environments, where subtle terminological distinctions carry operational significance.
Signal-to-noise (SNR) ratio is equally important. Retrieving loosely related documents increases token usage and introduces ambiguity into the prompt. Excessive noise often results in diluted or partially grounded responses. Evaluation must consider both recall and precision. Monitoring retrieval drift as documents are added, restructured, or re-embedded is also critical. Retrieval performance can degrade gradually as the knowledge base evolves, and without systematic measurement, such degradation may go unnoticed.
Faithfulness (groundedness): Is the answer strictly supported by evidence?
Faithfulness measures whether retrieved passages directly support each material statement in the generated response. The objective is traceability; every claim should be verifiable against a specific source text.
Grounding errors occur when the model introduces unsupported facts, extrapolates beyond retrieved evidence, or blends fragments from multiple documents into an inaccurate synthesis. Fluent responses can conceal these issues. Independent audits of generative search systems have shown that only 51.4% of generated sentences were fully supported by citations, demonstrating how easily confidence can outpace verifiable evidence [3]. Automated entailment checks and citation alignment scoring provide a first layer of validation, but high-impact workflows often require structured human review. Evaluation must identify unsupported claims at the sentence or claim level rather than relying solely on overall answer quality.
Answer relevance: Does the response address the intended question?
Answer relevance examines whether the generated response directly resolves the user’s query. A system may retrieve appropriate documents and remain grounded in them, yet still produce an incomplete, overly broad, or misaligned response.
Evaluation in this dimension requires a clear definition of expected outcomes for representative query sets. Domain experts typically annotate correct answers based on business intent rather than lexical similarity. Scoring frameworks may incorporate structured grading rubrics that assess completeness, scope, accuracy, and adherence to instruction. Complex enterprise queries often contain conditional clauses, cross-references, or multi-part requirements.
Each of the three dimensions maps to a corresponding layer in the system architecture:
- Retrieval-layer evaluation isolates the vector-search and ranking mechanisms. It measures recall, ranking quality, embedding alignment with domain terminology, and performance stability as the corpus evolves. Synthetic benchmarks alone are insufficient; representative real-world queries must form the basis of testing.
- Generation layer evaluation focuses on grounding fidelity, logical consistency, completeness, and adherence to formatting or compliance constraints. Separating generation analysis from retrieval clarifies whether errors originate from document selection or response synthesis.
- End-to-end system evaluation integrates both layers and measures task-level success under realistic operating conditions. It captures interactions between retrieval and generation, monitors drift over time, and evaluates performance under production load. Task success rate, correction frequency, and escalation patterns provide practical indicators of reliability.
A comprehensive RAG evaluation framework requires structured metrics at each layer and continuous monitoring after deployment. Only by measuring retrieval precision, grounding fidelity, and intent alignment together can the system’s reliability be quantified in terms that align with operational risk and accountability.
Key RAG evaluation metrics
A reliable RAG evaluation framework must reflect the system's architecture. Since a RAG pipeline consists of a retriever, a generator, and their interaction, evaluation must be structured across three layers: retrieval quality, generation quality, and end-to-end coherence.
Retriever evaluation metrics
Retriever evaluation measures how effectively the system identifies and ranks relevant documents from the knowledge base. Retrieval performance defines the factual boundary within which the generator operates. If critical evidence is not retrieved, generation accuracy cannot compensate for it.
To assess retrieval performance rigorously, standardized ranking and relevance metrics are applied. These measures expose blind spots in coverage, ranking inefficiencies, and noise in the retrieved context.
- Recall-at-k measures the proportion of all relevant documents among the top K retrieved results. It answers a completeness question: did the system retrieve all necessary evidence? High recall is essential in workflows where missing a single clause, regulation, or contractual reference can alter the outcome. Low recall indicates systematic blind spots in embeddings, indexing, or query formulation.
- Precision-at-k measures the proportion of relevant documents among the top K retrieved results. It quantifies how much of the retrieved context is actually useful. Low precision increases noise in the prompt, raises token costs, and introduces ambiguity into generation. High precision improves signal clarity and stabilizes answer quality.
- Mean reciprocal rank (MRR) evaluates how early the first relevant document appears in the ranking. It measures ranking efficiency rather than completeness.
- Normalized discounted cumulative gain (NDCG) evaluates ranking quality across graded relevance levels. It rewards highly relevant documents appearing near the top and penalizes relevant documents placed lower in the list. It provides a more nuanced assessment than binary relevance metrics and is particularly useful when multiple documents contribute partial evidence.
- Information-centric metrics: Knowledge F1 (K-F1) measures token-level overlap between retrieved context and verified ground-truth knowledge. It offers fine-grained validation of factual coverage. Timeliness evaluates whether retrieved documents reflect the most current version of information.
Generator evaluation metrics
Generator evaluation assesses how effectively the language model synthesizes a response using retrieved context. Even with strong retrieval performance, generation errors can introduce risk.
- Faithfulness (groundedness): Faithfulness measures whether retrieved documents directly support every material claim in the response. Unsupported additions, inferred assumptions, or misinterpretations indicate a risk of hallucinations. It is central to high-impact use cases.
- Answer relevance: Answer relevance evaluates whether the response addresses the user’s query in scope and intent. A response may be fully grounded yet incomplete or misaligned with the question. Relevance assessment verifies that the model resolves the actual task rather than producing adjacent information.
- Context utilization evaluates whether the model actually uses retrieved documents when generating a response. High retrieval accuracy alone does not guarantee grounded outputs, as models may ignore provided context and rely on internal knowledge. This metric verifies that claims are supported by retrieved sources, that relevant context is incorporated rather than skipped, and that the final answer depends on external data rather than unsupported reasoning.
- Traditional NLP metrics: ROUGE (Recall-oriented understudy for gisting evaluation) and BLEU (Bilingual evaluation understudy) measure lexical overlap between generated output and a gold reference answer. They assess surface similarity but do not validate grounding. Their usefulness depends on the availability of high-quality reference answers and is limited in dynamic enterprise settings.
- Semantic similarity: Embedding-based similarity metrics evaluate meaning alignment rather than exact wording. They are more robust to paraphrasing and stylistic variation. Semantic similarity supports correctness assessment but cannot independently detect hallucination.
Operational RAG metrics
Beyond retrieval and generation accuracy, production RAG systems must be evaluated against operational constraints that determine whether the system can function reliably at scale. The RAG evaluation metrics, like performance stability, resilience to edge conditions, cost efficiency, and security posture, must all be measurable.
System performance
Latency directly affects user experience and workflow integration. Total response time measures how long it takes to deliver a complete answer under realistic load conditions. Time to First Token (TTFT) isolates the delay before the model begins responding, which strongly influences perceived responsiveness. Monitoring both metrics under production load is essential, as laboratory benchmarks often underestimate real-world variance. Production-grade RAG evaluation must operate within an AI-ready infrastructure capable of handling indexing updates.
Reliability
Negative rejection measures whether the system correctly declines to answer when the retrieved context is insufficient. In high-stakes use cases, an explicit refusal is preferable to a speculative answer. A reliable RAG system must distinguish between “no answer available” and incomplete evidence.
Noise robustness evaluates how well the generator handles irrelevant or partially related documents within the retrieved context. Real retrieval pipelines rarely produce a perfectly clean context. The model must maintain focus on relevant evidence without being misled by distractors.
Safety and toxicity
RAG systems must be evaluated not only for correctness but also for safe and controlled behavior, as even grounded responses can include biased, harmful, or sensitive outputs if safeguards are not enforced. Safety evaluation covers the detection of toxic or harmful language, the identification of bias or unfair representations, the prevention of sensitive or restricted data exposure, and resilience to prompt injection or adversarial inputs embedded in queries or retrieved documents. Modern evaluation pipelines use LLM-based judges and specialized classifiers to assess safety at scale, enabling automated validation across large datasets while reserving human review for high-risk cases.
Instruction adherence
Instruction adherence evaluates whether a RAG system follows explicit output constraints required for structured workflows such as automation, reporting, or API integration, where a response can be accurate and grounded but still fail if it does not comply with required instructions. This includes verifying that the model follows formatting rules such as JSON, tables, or bullet structures, includes mandatory elements like citations or references, respects constraints such as length, tone, or step-by-step reasoning, and prioritizes system instructions over conflicting retrieved content.
For example, a system instructed to return a JSON response with cited sources becomes unusable if it instead produces free text, regardless of correctness. Evaluation is typically performed using LLM-as-a-judge approaches with structured scoring rubrics that measure compliance against defined requirements.
Cost management
Operational viability requires monitoring infrastructure consumption. Graphics processing unit (GPU) and central processing unit (CPU) utilization, token usage, and external API costs must be tracked for each query and each validated answer. Cost per validated answer provides a more meaningful indicator than raw token consumption, as it connects infrastructure expense to measurable output quality.
Security
Sensitive data leakage testing verifies that the system does not expose confidential or restricted information from the knowledge base to unauthorized users. Access control logic and contextual filtering must be evaluated alongside model behavior. Prompt injection resilience measures the system’s resistance to malicious or manipulative instructions embedded within retrieved documents or user inputs. The RAG evaluation tests whether guardrails and instruction hierarchy are enforced consistently.
Robust RAG evaluation frameworks
The well-designed frameworks share three characteristics: they support component-level analysis (retriever and generator), enable automated scoring at scale, and integrate with CI/CD and production monitoring.
Below are the most relevant frameworks for production-grade RAG systems.
RAGAS (Retrieval-Augmented Generation Assessment)
RAGAS is one of the most widely adopted open-source frameworks designed specifically for RAG systems. A key advantage is its reference-free design, which allows evaluation without requiring gold answers. This makes it suitable for dynamic enterprise knowledge bases where maintaining large labeled datasets is impractical. RAGAS is particularly useful for benchmarking retrieval configurations, monitoring hallucination risk, and performing regression testing across model versions.
The framework is built around three interdependent dimensions: context relevance, faithfulness, and answer relevance. When context relevance is weak, the issue resides in retrieval quality or ranking logic. When faithfulness breaks down, generations introduce unsupported content. When answer relevance drops, prompt design, instruction handling, or query interpretation may require adjustment. Evaluating all three dimensions clarifies where corrective action should be applied.
DeepEval
DeepEval is a Pytest-style framework built for automated evaluation within CI/CD pipelines. It supports unit testing of RAG components, custom metrics such as G-Eval, hallucination detection, and synthetic dataset generation.
Its strength lies in operationalization. Evaluation becomes part of the development lifecycle rather than a separate validation step. This approach enables systematic regression detection when embeddings, prompts, or retrievers change.
TruLens
TruLens focuses on tracing and observability. It instruments the RAG pipeline to capture intermediate states, allowing inspection of retrieved context, prompts, and generated responses. Built-in feedback functions measure groundedness and relevance in real time. TruLens is valuable for diagnosing the origin of failure. It helps determine whether errors stem from retrieval quality, prompt construction, or generation behavior.
RAGChecker
RAGChecker provides claim-level analysis of generated responses. It decomposes answers into individual statements and evaluates each against the retrieved context using entailment checks. This granular analysis is particularly useful in high-stakes domains where partial correctness is insufficient and unsupported claims must be identified explicitly.
ARES (Automated Evaluation Framework for RAG)
ARES introduces an automated evaluation pipeline that uses synthetic data generation and lightweight judge models. It employs statistical calibration methods such as Prediction-Powered Inference to reduce reliance on large-scale human annotation while maintaining metric reliability.
Building a production-grade RAG evaluation framework requires more than isolated metrics. It demands architectural isolation, calibrated datasets, and continuous monitoring aligned with your domain risk profile.

RAG evaluation methodologies
A RAG system must be evaluated across its architecture, its outputs, and its real-world behavior. While many techniques exist, three methodologies form the foundation of rigorous RAG assessment: component-level evaluation, LLM-as-a-judge scoring, and human-in-the-loop validation. Together, RAG evaluation methods provide structural diagnostics, scalable measurement, and domain-level assurance.
1. Component-level evaluation
Component-level evaluation isolates the retrieval and generation stages to determine where failures originate. Without isolation, end-to-end testing can obscure root causes.
Retriever evaluation applies established information retrieval metrics such as Precision-at-k, Recall-at-k, Hit Rate, and NDCG-at-k. A ground-truth dataset defines which documents or chunks should be retrieved for each query. The objective is to measure signal quality, ranking effectiveness, and coverage. Retrieval errors cap system performance regardless of generator quality.
Generator evaluation assesses how well the LLM uses retrieved context. Key dimensions include faithfulness (groundedness), answer relevance, and correctness. Claim-level entailment checks are often used to verify whether each material statement in the response is supported by retrieved evidence.
Component isolation enables targeted optimization. For example, low recall typically indicates deficiencies in embedding models or indexing strategy. By contrast, hallucinations usually signal generation misalignment. Similarly, consistent misinterpretation of user intent often points to issues in prompt design or instruction handling.
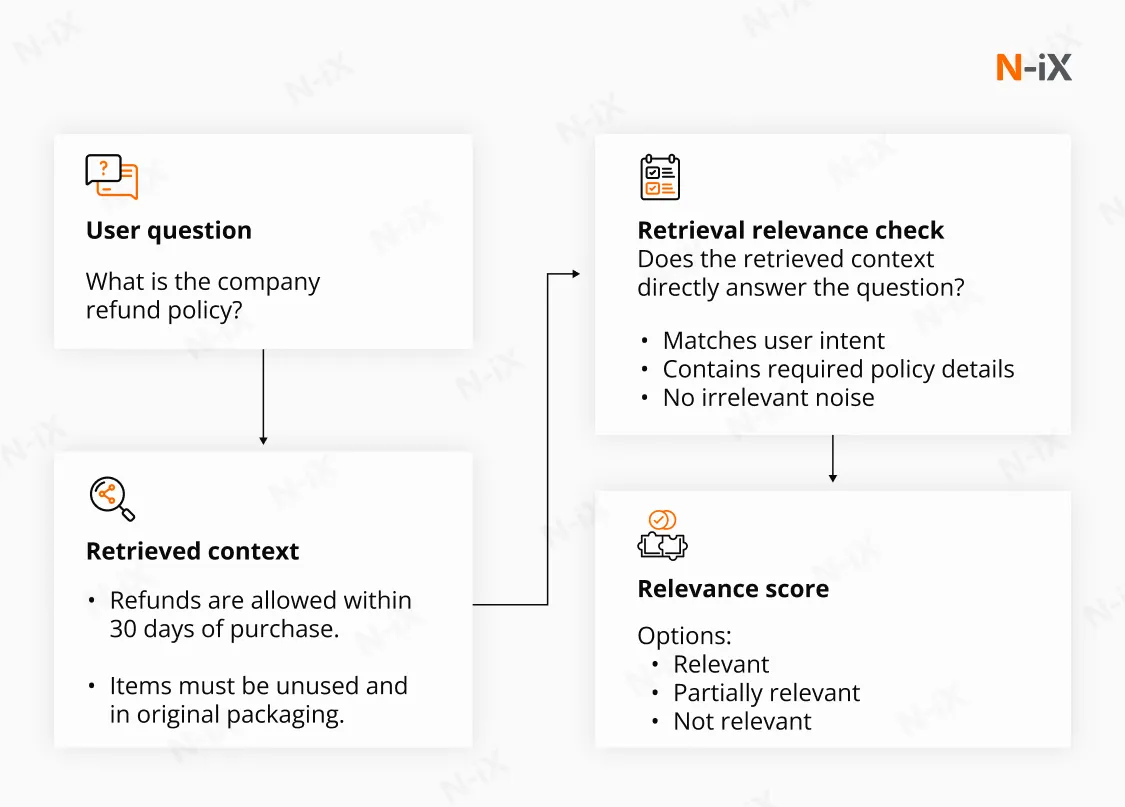
2. LLM-as-a-judge
LLM-as-a-judge uses a language model to score system outputs against predefined evaluation rubrics. Rather than relying solely on lexical overlap with a gold answer, the judge model evaluates semantic alignment, grounding, and relevance.
Scoring typically covers:
- Context relevance;
- Faithfulness;
- Answer relevance;
- Correctness or completeness.
This methodology supports reference-free evaluation, making it suitable for dynamic knowledge bases where maintaining large labeled datasets is impractical. It also enables large-scale regression testing and production monitoring.
However, automated judging requires carefully designed prompts and calibration. Bias, inconsistency, and over-reliance on model reasoning can distort results. Strong implementations combine structured scoring rubrics with periodic human validation to maintain reliability.
3. Human-in-the-loop validation
Automated scoring cannot fully replace expert judgment, particularly in high-stakes domains. Human-in-the-loop evaluation involves subject matter experts reviewing sampled outputs to assess factual accuracy, nuance, and contextual appropriateness.
Within this methodology, experts examine:
- Whether retrieved documents truly support the answer;
- Whether the response omits critical constraints;
- Whether subtle misinterpretations or overgeneralizations occur.
Human validation is essential when legal or reputational risks are present. It also serves as calibration for automated metrics and provides qualitative insights that quantitative scores may miss. Although manual review does not scale easily, strategic sampling combined with automated filtering makes it operationally feasible.
RAG evaluation does not end after initial validation. It must be embedded across the system lifecycle, from early experimentation to post-deployment monitoring.
|
Lifecycle stage |
Primary purpose |
Evaluation focus |
|
Development |
Validate architectural choices and experiment impact |
Retrieval quality, faithfulness, answer correctness |
|
Stress testing |
Assess robustness before production release |
Edge cases, hallucination detection, prompt injection resistance |
|
Monitoring |
Detect drift and quality degradation in live usage |
Faithfulness, safety, negative rejection, latency |
|
Regression testing |
Prevent performance drops after updates |
High-risk scenarios, known failure patterns |
Challenges and limitations in evaluating RAG systems
Even with well-defined metrics and tooling, evaluating RAG systems in production introduces structural challenges that extend beyond model accuracy.
Ground truth and benchmarking constraints
RAG evaluation depends on high-quality question–answer–context datasets, which are expensive and difficult to maintain. Unlike standard LLM testing, validation requires mapping each query to a correct answer and the specific supporting passages. Changes in chunking, embeddings, or indexing invalidate prior labels, forcing repeated annotation cycles. Public benchmarks provide comparability but rarely reflect domain nuance, freshness requirements, or multi-step reasoning typical of production systems.
Retriever performance under production conditions
Retriever metrics often look strong offline but degrade in real corpora filled with hard negatives. Incomplete relevance labeling further distorts recall and precision calculations. At scale, Approximate Nearest Neighbor search introduces unavoidable trade-offs between latency and retrieval completeness. Evaluation must therefore account for ranking quality, coverage, and infrastructure constraints simultaneously. Measuring retrieval in isolation without production-scale validation creates false confidence.
In one enterprise-scale RAG deployment focused on product documentation, search initially failed to retrieve the relevant topic in 47% of evaluated queries. It illustrates how retrieval performance can degrade significantly outside controlled benchmarks [2].
Generator variability
Even with correct context, generation can introduce omissions, overgeneralizations, or unsupported synthesis. Multi-hop reasoning amplifies this risk. Automated LLM-based judges enable scalable evaluation but introduce biases, such as a preference for verbosity and positional effects. Lexical metrics fail to capture grounding, while embedding similarity does not guarantee factual support. Non-deterministic decoding further complicates reproducibility. Generator evaluation requires claim-level verification and calibration against expert judgment to remain reliable.
Operational exposure
RAG systems must be evaluated for adversarial and compliance risks. Prompt injection, sensitive data leakage, and counterfactual manipulation require dedicated stress testing. Production environments also impose operational constraints: large-scale automated judging increases cost, and human review does not scale easily. Multilingual and domain-specific deployments add additional complexity.
Best practices for evaluating RAG systems by N-iX
At N-iX, we evaluate RAG systems the same way we build them: systematically, with measurable criteria and architectural transparency. Here are our best practices for RAG implementation.
- We isolate failure at the architectural level. We evaluate embedding models, retrievers, rerankers, and generators independently before validating the pipeline end-to-end, allowing precise root-cause analysis.
- We design domain-calibrated evaluation datasets. Rather than relying on generic benchmarks, we construct production-aligned query–context–answer sets that reflect real user behavior, domain terminology, edge cases, and multi-hop reasoning scenarios.
- We operationalize the RAG Triad in every assessment. Context relevance, faithfulness, and answer relevance are measured together to diagnose whether degradation stems from evidence selection, synthesis, or task resolution.
- We combine LLM-based scoring with expert calibration. Automated judges enable scale, but we regularly validate and recalibrate them against subject matter experts to eliminate bias.
- We perform controlled iterative optimization. Only one variable, chunking strategy, embedding model, reranking logic, or prompt template, is modified per experiment.
- We embed security and robustness testing into evaluation cycles. Prompt injection resistance, sensitive data leakage checks, adversarial distractor handling, and negative rejection capability are validated before production release.
- We integrate evaluation into CI/CD and AI observability workflows. Retrieval quality, groundedness, latency, token usage, and drift signals are continuously monitored to prevent silent performance regression after deployment.
Our evaluation methodology translates into measurable operational impact. During one of our projects delivered to an automotive provider, we reduced hardware test plan preparation costs by 15x while dramatically accelerating document creation. In logistics, RAG-powered copilots reduced routine task execution time by up to 50%. It leads to improving workforce efficiency without compromising compliance or accuracy.
If you are developing or scaling a RAG solution and require production-grade evaluation aligned with your domain, security posture, and performance targets, our AI engineering experts are ready to support you.

FAQ
What is RAG evaluation, and why is it important?
RAG evaluation is the process of systematically assessing how well a retrieval-augmented generation system retrieves relevant information and generates accurate, grounded responses. It measures retrieval quality, answer correctness, faithfulness to source documents, and overall task performance. Without structured evaluation, RAG systems may produce fluent but unsupported answers, leading to compliance, reputational, or operational risks.
How do you measure the quality of a RAG system?
The quality of a RAG system is measured across three dimensions: retrieval performance, generation performance, and end-to-end alignment. Retrieval quality is evaluated using metrics such as Precisionat-k, Recall-at-k, and ranking effectiveness. Generation quality focuses on faithfulness, answer relevance, and factual correctness relative to the retrieved context. End-to-end evaluation verifies that the final response fully resolves the user’s question without hallucinations or omissions.
What are the most common problems in RAG systems?
The most common RAG issues include retrieving irrelevant or incomplete context, generating unsupported claims, and failing on multi-hop reasoning queries. Poor chunking strategies and weak embedding models often reduce retrieval accuracy. Even with correct context, language models may omit critical details or introduce subtle distortions.
What is the RAG Triad, and how does it help in evaluation?
The RAG Triad is a framework used to assess alignment between the query, retrieved context, and generated response. RAG evaluation evaluates context relevance, faithfulness to retrieved evidence, and answer relevance to user intent. By analyzing these three dimensions together, evaluators can identify whether failures originate in retrieval, generation, or task interpretation. The triad provides a structured method for diagnosing and improving the reliability of RAG systems.
References
- Classifying and Addressing the Diversity of Errors in Retrieval-Augmented Generation Systems - Xueying Zhang Stephen Rose Jesse C. Cresswell
- Optimizing and Evaluating Enterprise Retrieval-Augmented Generation (RAG): A Content Design Perspective - Sarah Packowski
- A Comprehensive Survey of Retrieval-Augmented Generation (RAG) Evaluation and Benchmarks: Perspectives from Information Retrieval and LLM - Northern Illinois University
Have a question?
Speak to an expert


