
The benefits of DataOps implementation are one of the main drivers of the fast-growing enterprise data management market. It is expected to grow from $9B in 2020 to $122.9B in 2025, according to Reportlinker. Poor data quality, lack of experts, and the inability to scale Big Data activities cause many data projects to fail.
How can DataOps methodology help you overcome these challenges and succeed with your Big Data project? And what is the right way to implement such a project? Let’s use one of N-iX's DataOps case studies as a real-life example, and find out.
DataOps as a key enabler of your data transformation journey
Data is probably one of the most important assets any organization has nowadays. However, even though most companies collect tons of data, many struggle to make proper use of it. This is usually caused by having to deal with vast amounts of raw data and lacking the appropriate tools to clean, structure, and apply it.
This is where DataOps services come in. It provides the necessary practices and methodologies that automate and streamline data flows within an organization. As a result, you get access to relevant data that you can apply in a variety of ways, from improving the services that you provide to increasing the efficiency of internal business processes.

DataOps case studies: A success story of global in-flight connectivity provider
Gogo is one of the world’s leading in-flight connectivity and entertainment providers with 16 commercial airline clients.
The challenge: vast amounts of unstructured data
Gogo’s connectivity equipment is installed aboard over 2,900 commercial aircraft. This equipment constantly provides data that the company uses to monitor and analyze the quality of services they provide.
Unfortunately, the sheer amount of data and the fact that it was received from different sources made analysis quite inefficient. In some cases, even impossible.
Furthermore, Gogo often received no-fault-found (NFF) equipment maintenance requests that led to significant losses in both time and costs. Without structured and consistent data, the company was unable to prove their hypothesis of what caused such requests.
Main takeaway. If your company collects vast amounts of data on a daily basis, you need powerful analytical tools to properly refine and utilize it.
The solution: a single unified DataOps platform
The DataOps journey of Gogo began back in 2017 when they approached N-iX to expand their capabilities for data development and support.
N-iX engineers provided the DataOps services to build a single unified cloud-based platform that collects and stores all data obtained from Gogo’s equipment. To achieve this, the team created an end-to-end delivery pipeline that orchestrated the full cycle of data analysis, from receiving equipment logs to analyzing, processing and storing the data in a cloud-based data lake.
Furthermore, the platform allowed N-iX engineers to apply Data Science and Machine Learning algorithms to create models for monitoring and predicting equipment malfunctions.
Main takeaway. DataOps services improve the structure of data flow within an organization and provide the capabilities necessary to effectively analyze and interpret data.
The benefit: saved costs and better-quality service
DataOps implementation provided Gogo with several significant tangible benefits. Firstly, the company can monitor and analyze their equipment more effectively. Access to comprehensive data from each installed piece of equipment allows Gogo to find patterns in its performance. As a result, the company can easily discover gaps and improve the overall quality of their services (speed, connection quality, etc.), making them even more appealing to customers.
Secondly, Gogo was able to greatly decrease their operational expenses. The improved quality of connectivity services reduced the number of penalties for ill-performing equipment that the company had to pay to the airlines.
Finally, the DataOps solution enabled Gogo to apply such advanced technologies as Machine Learning and AI. This boosted their analytical capabilities even further and allowed the company to discover and predict the causes of equipment malfunctions. This also led to a significant reduction in maintenance costs that were spent on handling no-fault-found requests.
Main takeaway. DataOps implementation streamlines data analysis and makes it more effective. It can help you find gaps and improve the services that you provide. This, in turn, can have many benefits, from more loyal customers to an expanded market reach and saved costs.

How to succeed in DataOps implementation
One of the key aspects that put Gogo in the list of successful DataOps case studies was a solid foundation that the company had prepared before starting the development. Preparation for implementing and taking advantage of the benefits of DataOps in your organization can be divided into three main components.
Understand the architecture of your data flow
If you are considering starting a DataOps project, it means that your business already has certain data pipeline architecture in place. To make full use of it, you must have a clear understanding of which data is collected, where it is coming from, where it is stored, and what happens to it afterward. Only then you can apply the DataOps methodologies to streamline and improve this process.
This task may prove to be challenging for many organizations. However, you can always find a reliable tech partner that will support you along the way. Consulting and Discovery Phases are particularly useful in such cases.

Clearly define end-goals
Data analysis for the sake of data analysis will not yield any substantial results. Before starting the DataOps project (or any project, for that matter), it is crucial to establish clear end goals that you are trying to achieve.
In the case of DataOps, this not only means knowing how to apply the results of your data analysis. You also have to be aware of how these results were found, and which results to expect.
Build a dedicated data engineering team
Any Big Data project requires a dedicated team of experts who would oversee it. It is crucial not to cut corners when it comes to forming your data engineering team. Providing it with enough capacity will prove to be invaluable for the success of your DataOps project.
Moreover, you have to make sure that the team covers all roles and responsibilities that the project requires. This includes data architects, business analysts, test engineers, etc.
Top 5 DataOps best practices for successful implementation
Years of experience with Big Data helped us find several DataOps best practices that significantly improve the chances of successful delivery of such projects. Let’s take a closer look.
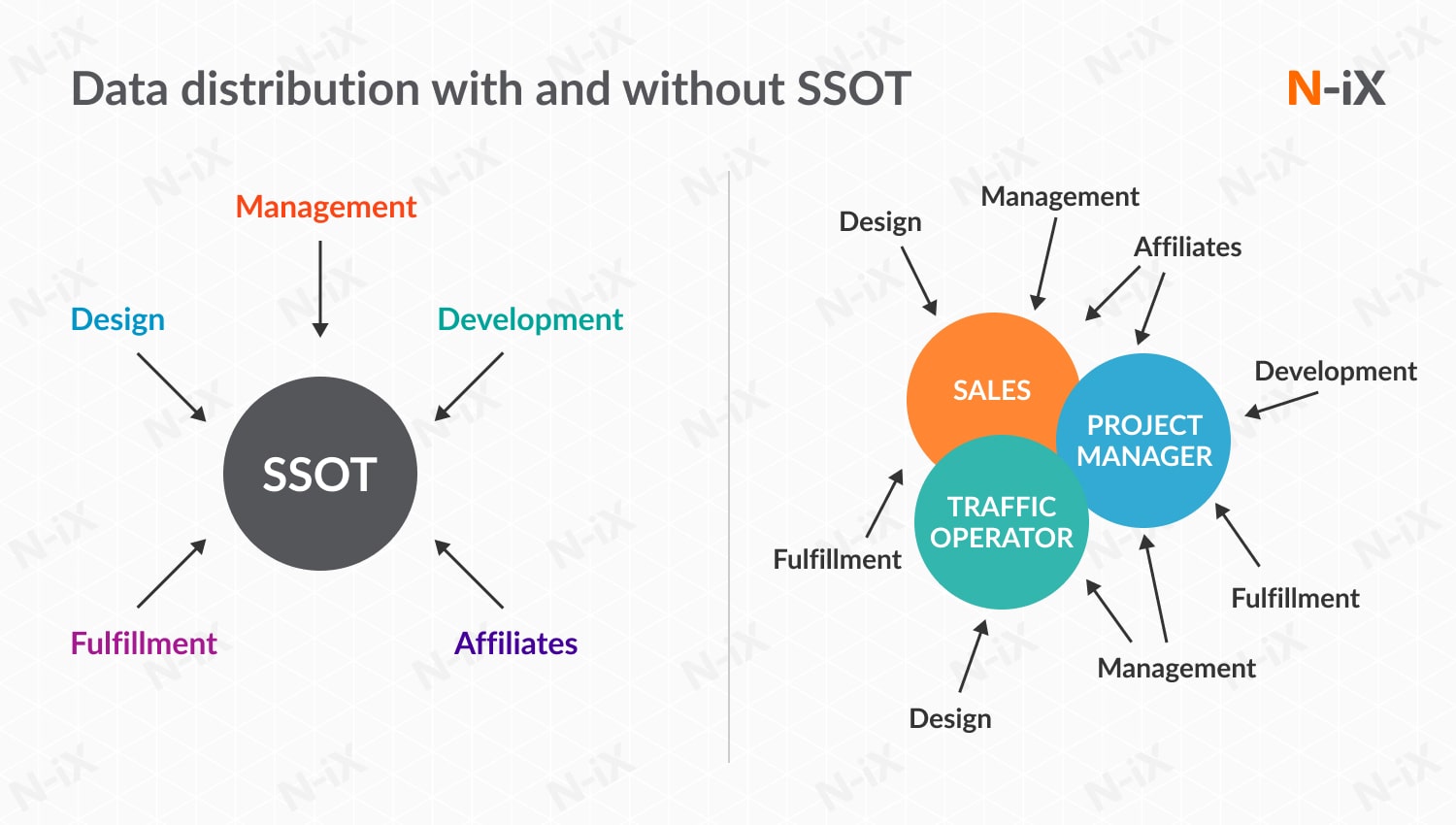
1. Single Source of Truth (SSOT) for data
When data is received from multiple sources, it becomes unstructured and disjointed. Not only does this make analysis problematic, even accessing the necessary data becomes a challenge.
Therefore, it is highly recommended to establish a unified environment (also known as a Single Source of Truth - SSOT) where all data will be collected. In addition to making data access easier, this will also ensure that everyone within your organization uses the same data - something equally as important.
2. Clear responsibility and response definition
Next on the list of DataOps best practices is clear allocation and documentation of all project roles and activities. These include but are not limited to:
- What the responsibilities of each DataOps team member are
- Which types of data are used for analysis
- How quickly and frequently the data should be analyzed
- Which data has more priority and should be analyzed first
- How to respond to bigger or lower amounts of data
- What to do if no data is received
This will ensure that the process of applying the DataOps methodology stays efficient even under unforeseen circumstances.
3. Effective communication between the team and project stakeholders
To be truly effective, your DataOps team must be fully aware of what they are working towards, i.e. project end-goals. Effective communication and feedback from the stakeholders are some of the best ways of achieving this. Planning discussions, knowledge-sharing sessions, and update reports can go a long way. If you are working with an outsourced team, business trips can also be quite useful. However, in times of the pandemic, they became less relevant.
We would like to draw particular attention to story mapping workshops, which are especially useful. These are meetings where project stakeholders share more insight and provide context for the entire engineering team about the upcoming development plans. These workshops can be organized by not only the stakeholders but the engineering team as well. In fact, such cases should be encouraged, as they show the team’s investment in your project.
4. Proper use of automation
Analyzing vast amounts of data involves many repetitive resource-intensive tasks. Clever use of automation in the DataOps strategy will free up your resources and bring about many benefits. These are as follows:
- Saved time and costs;
- Increased efficiency and speed of data analysis;
- Fewer errors caused by the human factor;
- Better data security and protection.
It is important to remember that automation may be a tricky process in itself and requires careful planning. Here are a few tips to keep in mind that will help with implementing it correctly.
- Prioritize automating tasks that require the least skill and the most time to complete;
- Do not try to automate everything, as it can lead to lower productivity;
- Put high emphasis on flexibility with a clever combination of open-source and third-party technologies;
- Make a long-term plan with clear end goals for your automation projects.
5. Knowledge retention
Becoming one of the successful DataOps case studies takes time. Naturally, over the course of development, they accumulate a lot of information (feature development plans, technological decisions, knowledge sharing notes, etc.). It is crucial not to lose this information and keep it organized since you might have to refer to it later.
Therefore, it is highly recommended that your engineering team keeps up-to-date documentation about their development activities. It does not have to be extremely comprehensive since creating such documentation would take up much of your team’s time. As long as it is clear and informative, even a bare minimum will suffice.

How N-iX DataOps services can help you make the best use of your data
- N-iX has vast experience in providing Big Data services with many successful DataOps case studies of large enterprises, including Gogo and a global MVNO Lebara;
- N-iX engineers have extensive expertise in some of the most popular Big Data technologies, including Hadoop and Apache Spark;
- We make sure that your data is always protected by complying with PCI DSS, ISO 9001, ISO 27001, and GDPR standards;
- Our company is a recognized and trusted name in the tech market, being included in various top software developer lists on platforms such as Clutch.co, GoodFirms.co, and others.


